
Gemini APIの利用制限を乗りこなす!429エラー対策と安定運用ノウハウ
はじめに:Gemini APIの可能性と直面する壁
AI技術は目覚ましい進化を遂げ、Gemini APIのような最先端モデルは、ビジネスや開発の可能性を広げています。対話型AI、コンテンツ生成、データ分析など、その応用範囲は日々拡大しています。しかし、その強力な能力を最大限に引き出そうとする際、開発者が避けて通れない共通の壁に直面します。それが「429 Resource Exhausted」エラー、つまり利用制限です。
このエラーは、APIへの過剰なリクエストにより発生し、サービスの停止やユーザー体験の低下に直結します。大規模プロジェクトにおけるGemini API活用では、安定稼働に向けた利用制限対策が不可欠です。
本記事は、利用制限を克服し、Gemini APIを安定かつ効率的に運用するための具体的な戦略と実践ノウハウを解説します。エラー回避に加え、サービスの品質向上とコスト最適化に資する情報を提供します。

「429 Resource Exhausted」エラーの正体と背景
「429 Resource Exhausted」エラーの具体的な意味と背景を理解します。
レートリミット(利用制限)とは何か?
APIにおけるレートリミットとは、一定時間内にユーザーまたはアプリケーションがAPIに送信できるリクエストの数や、処理できるデータの量に設定された上限のことです。Gemini APIでは、主に以下の要素が制限の対象となります。
- QPM (Queries Per Minute): 1分間あたりのリクエスト数。
- TPM (Tokens Per Minute): 1分間あたりに処理できるトークン(文字や単語の単位)の数。
- RPM (Requests Per Minute): QPMと同じ意味で使われることもあります。
これらの制限は、APIプロバイダーが安定したサービスを提供し、すべてのユーザーに公平にリソースを配分するために不可欠です。
Gemini APIにおける具体的な利用制限の種類と公式ドキュメントの参照方法
Gemini APIの利用制限は、Google Cloudの各プロジェクトや、使用するモデル(例: Gemini 1.5 Flash, Gemini 1.5 Pro)によって異なります。最新かつ正確な情報は、必ず公式ドキュメントを参照してください。開発開始時や新モデル導入時には、常にこのドキュメントを確認します。特に、モデルごとのQPMやTPMの違いは、システム設計に大きな影響を与えるため重要です。
なぜ利用制限が必要なのか?
利用制限が設けられる主な理由は以下の通りです。
- システム安定性: 無制限のリクエストはサーバーに過負荷をかけ、サービス全体のダウンやパフォーマンス低下を引き起こす可能性があります。
- 公平なリソース配分: すべてのユーザーが一定の品質でAPIを利用できるように、リソースを公平に分配します。
- セキュリティ: DDoS攻撃のような悪意のある行為からAPIを保護する役割も果たします。
エラーメッセージの構造を理解し、デバッグに活かす方法
「429 Resource Exhausted」エラーが発生した場合、通常、レスポンスボディには詳細な情報が含まれています。
{
"error": {
"code": 429,
"message": "Resource exhausted. Your project exceeded the rate limit for the API. Please see https://cloud.google.com/vertex-ai/docs/generative-ai/quotas/generative-ai-quotas for more information.",
"status": "RESOURCE_EXHAUSTED",
"details": [
{
"@type": "type.googleapis.com/google.rpc.ErrorInfo",
"reason": "RATE_LIMIT_EXCEEDED",
"domain": "generativelanguage.googleapis.com",
"metadata": {
"service": "generativelanguage.googleapis.com",
"consumer": "projects/YOUR_PROJECT_NUMBER",
"quota_limit": "token_per_minute_per_project_requests",
"quota_limit_value": "300000",
"quota_metric": "generatelanguage.googleapis.com/tokens",
"rate_limit_exceeded_details": "Quota 'token_per_minute_per_project_requests' exceeded. Limit: 300000 tokens/min."
}
}
]
}
}
この例では、「Quota 'token_per_minute_per_project_requests' exceeded. Limit: 300000 tokens/min.」というメッセージから、トークン制限を超過したことが明確に分かります。quota_limitやquota_metricの情報を確認することで、どの種類の制限に引っかかったのかを特定し、デバッグの強力な手掛かりとすることができます。この詳細情報は、トークン数の最適化やリクエスト頻度の調整における強力な手がかりとなります。

実践的対策1:APIキーの戦略的分離とリクエスト分散
API利用制限への最初の、そして最も効果的な対策の一つは、APIキーの戦略的な管理とリクエストの分散です。
単一APIキー利用のリスクと限界
一つのプロジェクトやアプリケーションで単一のAPIキーを使用している場合、そのキーに割り当てられたレートリミットを簡単に超えてしまうリスクがあります。例えば、異なる機能が同じキーを使用している場合、一つの機能での急激なリクエスト増加が、他の機能にまで影響を及ぼし、全体としてサービス停止のリスクを高めます。これは、初期段階で直面する一般的な課題の一つです。
プロジェクト、機能、あるいはユーザー単位でのAPIキー分離の推奨とそのメリット
APIキーの戦略的な分離が推奨されます。
- プロジェクト単位: 複数のプロジェクトがある場合、それぞれに独立したAPIキー(およびGoogle Cloudプロジェクト)を使用します。
- 機能単位: 例えば、コンテンツ生成機能とチャットボット機能で別々のAPIキーを使用します。これにより、それぞれの機能が独立したレートリミットを持つことができます。
- ユーザー(テナント)単位: SaaSのようなマルチテナントアプリケーションでは、テナントごとにAPIキーを分離することで、あるテナントの利用が他のテナントに影響を与える「ネイバーノイズ」問題を回避できます。
これにより、各APIキーが独立したレートリミットを持つため、一つのリミットを超過しても他の機能が停止するのを防ぎ、システム全体の堅牢性が向上します。
大規模なシステムにおけるAPIキー管理とルーティングのベストプラクティス
大規模システムでは、数百、数千のAPIキーを管理する必要が出てくることもあります。このような場合、以下のプラクティスが有効です。
- APIキーの自動プロビジョニング: CI/CDパイプラインや専用の管理ツールを用いて、APIキーの生成、配布、ローテーションを自動化します。
- セキュアなストレージ: APIキーは環境変数、シークレットマネージャー(例: Google Secret Manager)、またはKMSで暗号化して保管します。コードに直接ハードコードすることは絶対に避けるべきです。
- ルーティングロジック: アプリケーション内で、どのAPIキーをどのリクエストに割り当てるかを決定するロジックを実装します。これはラウンドロビン、負荷分散、あるいは特定のユーザーグループへの割り当てなど、要件に応じて設計します。
APIゲートウェイやプロキシを利用したリクエスト分散のアーキテクチャパターン
より高度なリクエスト分散を実現するために、APIゲートウェイやプロキシサーバーの導入を検討します。
アーキテクチャの概念:
- アプリケーションからのAPIリクエストは、直接Gemini APIには送られず、APIゲートウェイを経由します。
- APIゲートウェイは、複数のGemini APIキーを管理し、ルーティングロジックに基づいて最適なAPIキーを選択します。
- ゲートウェイは、リクエストのキューイング、レート制限の適用(アプリケーション側での二次的な制限)、リトライ処理なども担当できます。
これにより、アプリケーション側はAPIキーの複雑な管理やリミット超過時のハンドリングを意識することなく、シンプルにAPIゲートウェイにリクエストを送ることができます。
具体的な実装例(擬似コードや概念図)による解説
以下は、複数のAPIキーをラウンドロビンで利用するシンプルなプロキシの擬似コード例です。
# Python pseudo-code for a simple API Key Rotator/Proxy
import itertools
import time
import requests
# 仮のAPIキーリスト。実際にはGoogle Secret Managerなどから取得
API_KEYS = [
"YOUR_API_KEY_1",
"YOUR_API_KEY_2",
"YOUR_API_KEY_3"
]
# APIキーを循環させるイテレータ
api_key_iterator = itertools.cycle(API_KEYS)
GEMINI_API_ENDPOINT = "https://generativelanguage.googleapis.com/v1beta/models/gemini-pro:generateContent?key="
def call_gemini_api(prompt_text: str):
max_retries = 5
current_api_key = next(api_key_iterator) # 次のAPIキーを取得
for attempt in range(max_retries):
try:
print(f"Attempt {attempt+1}: Using API Key {current_api_key[-4:]}...") # 末尾4桁のみ表示
headers = {
"Content-Type": "application/json"
}
payload = {
"contents": [
{
"parts": [
{"text": prompt_text}
]
}
]
}
response = requests.post(
f"{GEMINI_API_ENDPOINT}{current_api_key}",
json=payload,
headers=headers
)
response.raise_for_status() # HTTPエラー(4xx, 5xx)を発生させる
return response.json()
except requests.exceptions.HTTPError as e:
if e.response.status_code == 429:
print(f"429 Resource Exhausted error with key {current_api_key[-4:]}. Retrying with next key or exponential backoff.")
current_api_key = next(api_key_iterator) # 次のキーに切り替え
time.sleep(2 ** attempt) # 指数バックオフ
else:
print(f"Other HTTP error: {e}")
raise
except requests.exceptions.RequestException as e:
print(f"Network or other request error: {e}")
raise
raise Exception("Failed to call Gemini API after multiple retries.")
# 利用例
# result = call_gemini_api("こんにちは、Gemini APIについて教えてください。")
# print(result)
この擬似コードは、429エラーが発生した場合に次のAPIキーに切り替え、同時に指数バックオフを適用する基本的なロジックを示しています。これにより、単一キーが制限に達しても、システム全体が停止するのを防ぎます。

実践的対策2:モデル選定とリクエストパターンの最適化
APIキーの分散だけでなく、使用するモデルの特性を理解し、リクエストパターンを最適化することも、利用制限を乗りこなす上で非常に重要です。
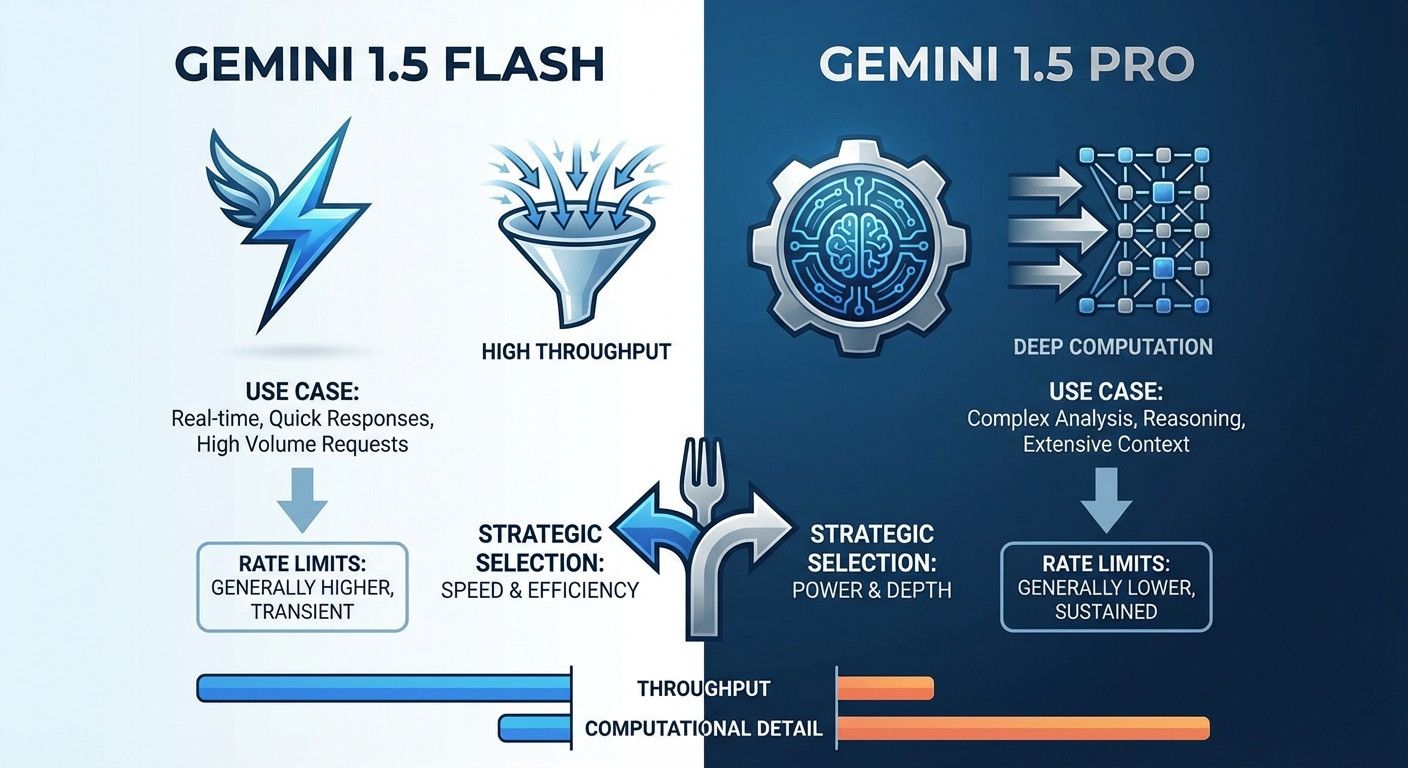
Geminiの異なるモデル(例: Gemini 1.5 Flash、Gemini 1.5 Pro)が持つ利用制限の違い
Gemini APIは、様々なユースケースに対応するために複数のモデルを提供しています。例えば、Gemini 1.5 Flashは高速かつ軽量で、大規模な並列処理や短い応答時間が求められるタスクに適しています。一方、Gemini 1.5 Proはより高度な推論能力と広いコンテキストウィンドウを持ち、複雑な分析や長文の生成に優れています。
これらのモデルは、それぞれ異なるレートリミットが設定されています。一般的に、FlashモデルはProモデルよりも高いQPMやTPMが設定されている傾向があります。これは、Flashがより多くのリクエストを処理できるように設計されているためです。
ユースケースに応じた最適なモデル選択の重要性(コスト、性能、そして制限のバランス)
強力なモデルが選択される傾向にありますが、それが常に最適とは限りません。
- 高速応答が最優先される場合(例: チャットボット、リアルタイムのサジェスト機能):Gemini 1.5 Flashのような軽量モデルを選択し、高いQPMを享受します。
- 複雑な推論や長文処理が必要な場合(例: レポート自動生成、コード生成):Gemini 1.5 Proのような高性能モデルを選択します。ただし、その分レートリミットは厳しくなることを考慮に入れます。
最適なモデル選択は、コスト(モデル利用料も異なる)、性能要件、そして利用制限のバランスを考慮して行うべきです。不必要に高性能なモデルを使うと、コストもかかり、利用制限にも早く達してしまいます。
バッチ処理、非同期処理、キューイングによるリクエスト集中回避策
リアルタイム性が求められない処理の場合、リクエストを集中させるのではなく、以下の方法で分散させることが有効です。
- バッチ処理: 複数の個別のリクエストを一つにまとめ、まとめてAPIに送信します。これにより、APIコール自体の回数を減らし、QPM制限への影響を軽減できます。
- 非同期処理: Webhookやメッセージキュー(例: Google Cloud Pub/Sub)を利用し、リクエストを非同期で処理します。ユーザーからの入力後すぐにAPIレスポンスを返す必要がない場合、これは非常に有効です。
- キューイング: リクエストをキューに格納し、一定の間隔で(または利用可能なレートリミット内で)順次APIに送信します。これにより、瞬間的なリクエストの急増による429エラーを防ぐことができます。特に、大量コンテンツの定期的生成など、バックグラウンド処理において有効な手法です。
指数バックオフ(Exponential Backoff)を用いた堅牢なリトライメカニズムの実装
429エラーは避けられないこともあります。そのような場合にシステムが堅牢であるためには、リトライメカニズムが不可欠です。単に数秒待ってリトライするのではなく、指数バックオフを実装することがベストプラクティスです。
指数バックオフとは、リトライ間隔を試行回数に応じて指数関数的に長くしていく方法です。これにより、APIサーバーへの負担を軽減しつつ、リソースが回復した後に成功する可能性を高めます。
import time
import requests
def call_api_with_exponential_backoff(url, payload, api_key, max_retries=8):
for i in range(max_retries):
try:
headers = {"Content-Type": "application/json"}
response = requests.post(f"{url}?key={api_key}", json=payload, headers=headers)
response.raise_for_status()
return response.json()
except requests.exceptions.HTTPError as e:
if e.response.status_code == 429:
wait_time = 2 ** i + (time.monotonic() * 0.1) % 1 # 指数的に待機時間を増加 + jitter
print(f"429 error. Retrying in {wait_time:.2f} seconds...")
time.sleep(wait_time)
else:
raise # Other HTTP errors are not retried
except requests.exceptions.RequestException as e:
print(f"Network error: {e}. Retrying...")
time.sleep(2 ** i + (time.monotonic() * 0.1) % 1) # ネットワークエラーもリトライ
raise Exception("Max retries exceeded for API call.")
# APIキーの分離と組み合わせて利用
# result = call_api_with_exponential_backoff(GEMINI_API_ENDPOINT, some_payload, current_api_key)
time.monotonic() * 0.1) % 1のような「ジッター」を追加することで、複数のクライアントが同時にリトライして再びスパイクが発生するのを防ぐことができます。
プロンプトエンジニアリングによるトークン数削減とAPIコール頻度低減の可能性
プロンプト自体の最適化も、利用制限対策に貢献します。
- 冗長な説明の排除: プロンプトが長すぎると、それだけ消費トークン数が増えます。必要な情報に絞り込み、簡潔に記述します。
- Few-shot学習の効率化: Few-shotの例を効果的に選び、最小限の例で最大の効果が得られるように調整します。
- チェーン思考(Chain-of-Thought)の最適化: 複雑なタスクを分解して複数のAPIコールにする場合、各ステップのプロンプトを効率化し、中間生成物のトークン数を最小限に抑えます。
- バッチ処理可能なプロンプトの設計: 複数の独立した質問を一つのAPIコールで処理できるようプロンプトを工夫することで、APIコール頻度を減らせる場合があります。
これらのプロンプトエンジニアリングの工夫は、消費トークン削減とモデル応答品質向上の双方に効果をもたらします。
効率的なデバッグと継続的なモニタリング戦略
利用制限を管理し、安定稼働を維持するためには、問題の早期発見と解決が不可欠です。そのためには、効率的なデバッグと継続的なモニタリング戦略が重要になります。
エラーメッセージとログから原因を特定する具体的なデバッグ手順
429エラー発生時には、以下の手順でデバッグを実施します。
- エラーメッセージの詳細を確認: 前述の通り、APIからのレスポンスに含まれる詳細なエラー情報(
quota_limit,quota_metricなど)をまず確認します。これが最も直接的な原因特定の手がかりになります。 - アプリケーションログの確認: どのAPIキーを使用していたか、どのようなプロンプトを送信したか、いつリクエストが送信されたか、といった情報をアプリケーションのログから確認します。
- タイムスタンプの比較: エラーが発生した時間帯に、リクエスト数が急増していないか、または予期せぬAPIコールのパターンが発生していないかを、アプリケーションログや監視ツールのタイムラインで確認します。
- 関係するシステムのログ確認: APIゲートウェイやプロキシを導入している場合は、そちらのログも確認し、どこでリクエストがブロックされたのか、または遅延が発生したのかを特定します。
APIリクエスト/レスポンス、タイムスタンプ、APIキーなどのログ出力のベストプラクティス
デバッグを効率的に行うためには、適切なログ出力が不可欠です。
- リクエストとレスポンスのサマリー: 送信したプロンプトの最初の数文字、レスポンスのステータスコード、エラーメッセージ、そして処理時間(レイテンシ)をログに出力します。機密情報を含む場合は、マスキングを施すことを忘れないでください。
- タイムスタンプ: すべてのログに正確なタイムスタンプ(UTC推奨)を付与し、分散システムでのログの相関分析を容易にします。
- APIキーの識別子: どのAPIキーが使われたか(キーの末尾数桁など)をログに出力します。これにより、どのキーのレートリミットが超過したかを素早く特定できます。
- リクエストID/トレースID: 可能であれば、リクエストごとに一意のIDを付与し、システム全体を横断してリクエストの流れを追跡できるようにします(分散トレーシング)。
Google Cloud Monitoring (Cloud Monitoring) やカスタムツールによるAPI利用状況の可視化
目視によるチェックだけでは限界があります。継続的なモニタリングのために、Google Cloud Monitoringを活用することをお勧めします。
- デフォルトのメトリクス: Cloud Monitoringでは、Vertex AI APIの利用状況に関する様々なメトリクスがデフォルトで収集されています。これには、リクエスト数、エラーレート(特に4xxエラー)、レイテンシなどが含まれます。
- カスタムダッシュボード: 重要なメトリクス(例: 特定のAPIキーごとのQPM、TPM)を視覚的に把握できるカスタムダッシュボードを作成します。これにより、異常な利用パターンやリミットへの接近を直感的に捉えることができます。
- ログエクスプローラ: Cloud Loggingで収集されたAPI関連のログをクエリし、特定の条件(例: 429エラーを含むログ)でフィルタリングして分析します。
これらのツールは、リアルタイムでの状況把握と潜在的な問題の早期発見に寄与します。
閾値ベースのアラート設定による429エラーの早期検知と対応フロー
最も重要なモニタリング戦略の一つが、アラートの設定です。
- 429エラーレートのアラート: 429エラーの発生頻度やエラーレートが一定の閾値を超えた場合に、Slack、メール、PagerDutyなどへ通知するアラートを設定します。
- QPM/TPM利用率のアラート: 各APIキーやプロジェクトのQPM/TPMが、設定された制限の80%や90%に達した場合にアラートを発生させます。これにより、実際にエラーが発生する前に対応を開始できます。
アラートを受け取った際の対応フローも事前に定義すべきです。誰が、どのような情報を元に、どのような手順で対処するのかを明確にすることで、迅速な問題解決に繋がります。例えば、「アラート受信 → 監視ダッシュボード確認 → ログ分析 → APIキー切り替えorモデル切り替えorリクエスト抑制」といったフローです。
利用傾向の分析と将来の負荷予測に基づいたリソース計画
過去のAPI利用傾向を定期的に分析することで、将来の負荷を予測し、適切なリソース計画を立てることができます。
- ピーク時の傾向: 一日、一週間、一ヶ月の中で、どの時間帯にAPI利用がピークに達するのかを把握します。
- 成長予測: ユーザー数の増加や新機能のリリースに伴い、API利用がどのように変化するかを予測します。
- クォータ調整リクエスト: 予測に基づいて、Gemini APIのクォータ増量をGoogle Cloudのサポートにリクエストする必要があるかを判断します。これは計画的に行う必要があり、即座に対応されるわけではないため、余裕を持った申請が重要です。
これらの分析と計画は、持続可能なシステム運用に不可欠です。

まとめ:Gemini APIを安定稼働させるためのロードマップ
本記事では、Gemini APIの「429 Resource Exhausted」エラーという開発者が直面する課題に対し、多角的な対策とノウハウを解説しました。主要なポイントをまとめます。
- APIキーの戦略的分離: 単一キーの限界を理解し、機能、プロジェクト、あるいはユーザー単位でAPIキーを分離することで、独立したレートリミットを確保し、システム全体の堅牢性を高めます。APIゲートウェイやプロキシによるルーティングと組み合わせることで、さらに効果的な分散が可能です。
- モデル選定とリクエストパターンの最適化: ユースケースに応じて最適なGeminiモデル(Flash vs Proなど)を選択し、コスト、性能、利用制限のバランスを取ります。リアルタイム性が不要な場合は、バッチ処理、非同期処理、キューイングを活用してリクエスト集中を回避します。
- 指数バックオフによる堅牢なリトライ: 429エラー発生時に、リトライ間隔を指数関数的に増加させることで、APIサーバーへの負担を軽減しつつ、処理の成功率を高めます。
- 効率的なデバッグと継続的なモニタリング: 詳細なログ出力、Google Cloud Monitoringを活用した可視化、閾値ベースのアラート設定により、問題の早期発見と迅速な対応を実現します。過去の利用傾向分析に基づいたリソース計画も重要です。
これらの対策は単独ではなく、相互連携により最大の効果を発揮します。開発・運用チームでこれらの知見を共有し、継続的にシステムを改善していくことが、Gemini APIを最大限に活用するために不可欠です。
Gemini APIは革新的なツールです。利用制限は、安定したサービス維持と公平なリソース配分を実現するための仕組みです。これらの制限を適切に管理することで、その真価を最大限に引き出し、質の高いアプリケーションやサービスの提供が可能となります。

コメント